Blog
VideoThat!
Automagically Generate a Music Video for Your Input Audio
2nd place DataHack winner 🥈, September 2019
By Dalya Gartzman, Orian Sharoni, Yaara Arkin, Yael Daihes, Roee Shenberg
VideoThat will automagically generate the perfect video compilation that fits impeccably to the theme song of your choice. The algorithm’s default choice is to create a video clip from Taylor Swift’s videos to an Arctic Monkeys song.
Every good algorithm needs a use case
It’s your best friend’s wedding, and you want to make something nice for them. You gathered all of your mutual friends and recorded a personal song full of inside jokes and memorable stories. Everything is almost ready! Now all you have to do is manually edit all the party videos you have to fit perfectly to the song!
Say what now??
Yup, sounds like a rather tedious task… Well, luckily, no need to do it manually anymore!
VideoThat to the rescue!

The premise
The underlying assumption for this project is that the input videos already have an audio that fits perfectly to them. Therefore, we can match between video segments and audio snippets from your theme song, by finding correlated audio patterns.
Beat Feature Extraction: Spectral Novelty
Our premise, then, is that matching the beat between the source material and the target song will yield a video that works well with the target song. The question is how to define beat matching, and our choice is to try to align as many note starts as possible.
When a note is played, intuitively, we’re adding sound. The naïve way to quantify this is to look at the amount of energy (RMSE) added to the signal. Or, in algorithmic terms, calculate the energy in short windows of time, then calculate the difference between the amounts of energy (delta RMSE), and only keep positive values as we’re looking for note starts (energy novelty).
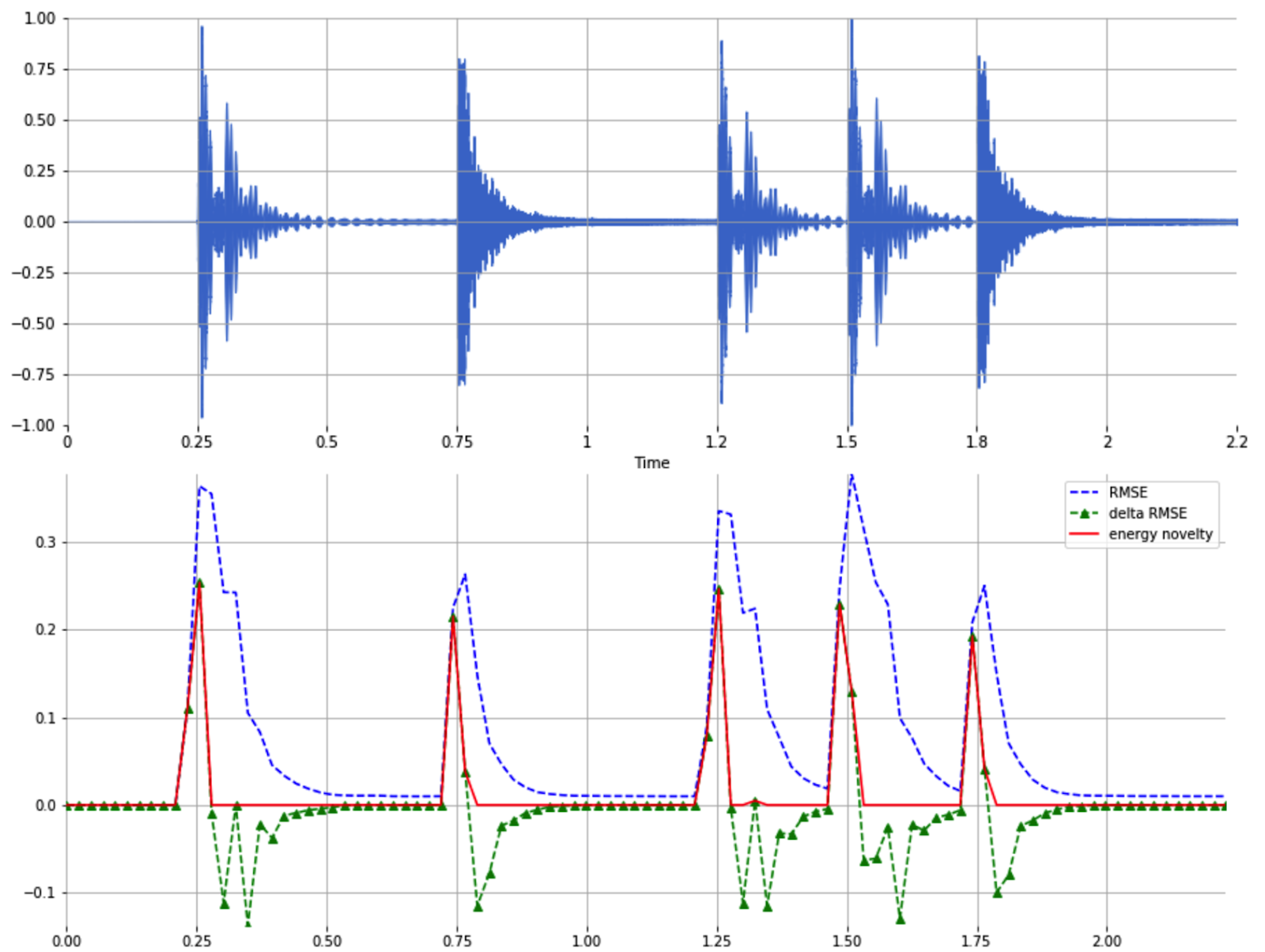
This works well if we only have one instrument playing one note at a time. Fortunately, that’s not usually the case in real music, so we extend the principle, by looking at energy in different frequency bands: if we play a new note while the old one is still fading away, we might be keeping the total amount of energy in the song the same, but the new note is higher or lower in frequency, so we’ll be able to detect the energy being added now.
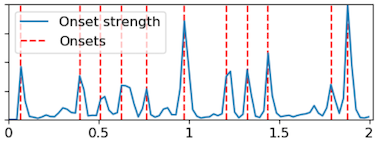
Librosa wraps this logic into librosa.onset.onset_strength, which yields a good signal for the task of detecting note onsets. If you want to be fun at parties, you can describe what it does as computing half-wave rectified spectral flux.
More resources: Reference with code examples, The source code for onset_strength
The pipeline
Before we can match between input videos segments and audio segments, we would first need to find those segments...
Segmenting videos can be done automatically, using the scenedetect python package.
Then, to generate a fingerprint for each audio segment at hand, we use librosa python package to discover onset patterns.
Scoring Function or: how to best match sound with scenes
Finally, working in a greedy manner, we match video segments to the theme song, by finding the unused video who’s audio is best correlated with the next segment in our theme song. To compute the correlation, we used a scoring function.
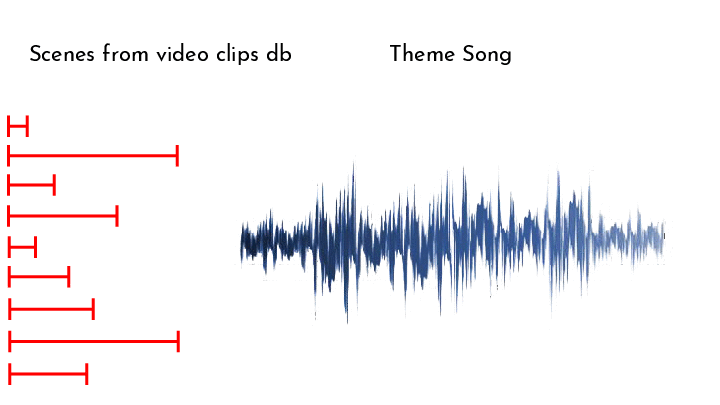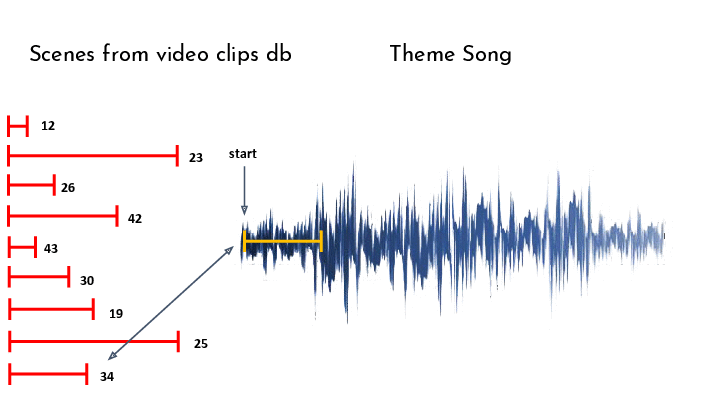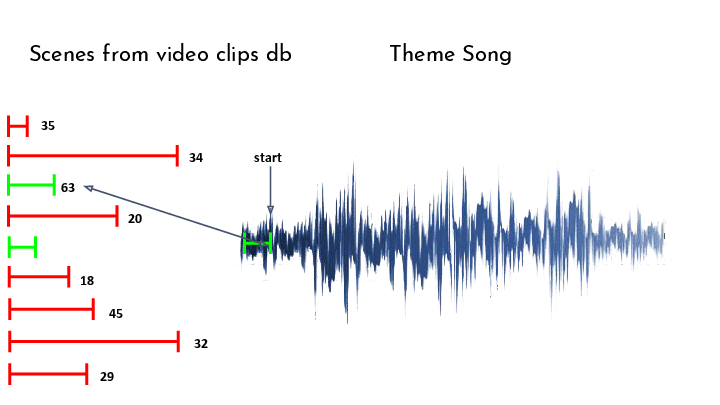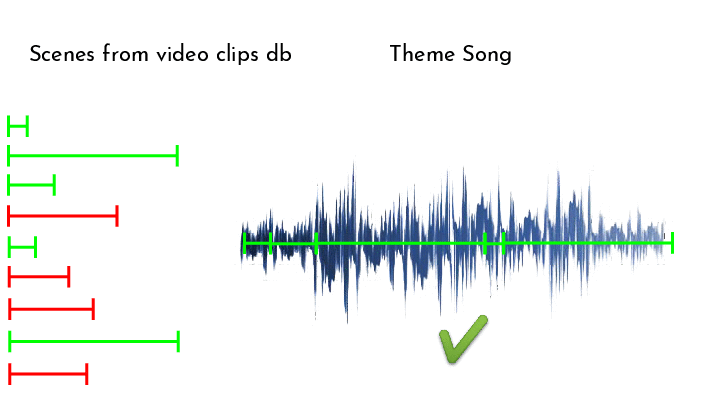
The scoring function we chose is based on the correlation between the spectral novelty of each clip and the spectral novelty of the target song. However, choosing the raw correlation is a poor choice in practice, because the spectral novelty is a non-negative quantity, which biases us towards longer clips since they have more chances of having notes align even if the beat doesn’t match.
To combat this, we can look at the rate of correlation, or ‘correlation per second’, by dividing the total correlation by the length of the clip we correlate to. This is also not the best, since it biases us towards short clips that align perfectly, while we do want longer matches that aren’t 100% on-beat for a more satisfying result.
In the end we chose to use a balanced approach of dividing the correlation by the square root of the length of the clip, which still biases towards longer clips, but gives short-but-good matches a fighting chance:
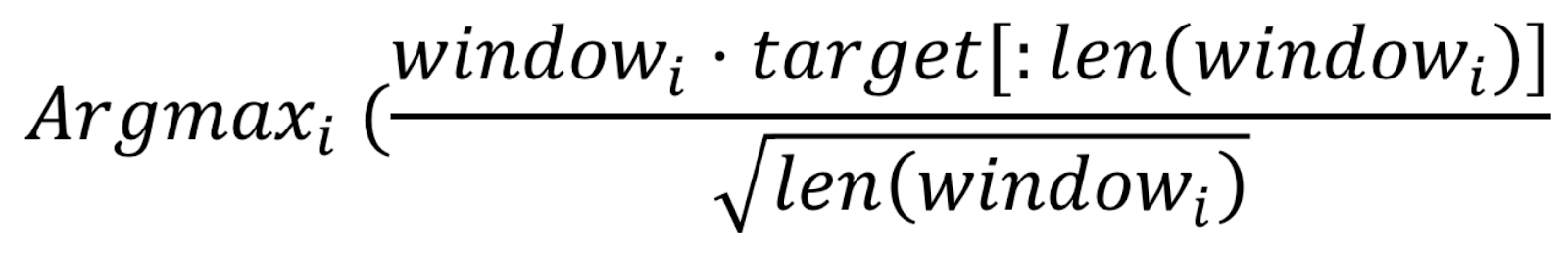
Alternative Solutions
You might ask yourself, why greedy? There has to be a better way to do this!
And indeed there is. There are in fact. Many better ways. As you can read on the next section, this project was tight in time, and quick wins were the expected result.
But still, we did try some different approaches, and thought of future ones:
Smarter search
Greedy search makes locally-good decisions that may be globally poor. A simple approach to rectifying this issue is to use a beam search in order to take more options into account. Another alternative would be to use a search strategy which is not sequential. For example, try to find globally good matching clips (e.g. "clip 7 matches the middle of the song well") and then fill in the spaces left.
Better score
There’s plenty of room to fudge around with the score (e.g. subtract a small amount from the spectral novelty so that a note compared with silence will actively penalize the score, and silence on silence will add to it)
Behind the scenes
This project was conceived, born and matured, during a 40 hour long Data Science Hackathon called DataHack (or as we like to call it in Israel - the yearly field trip of Data Science), held in Jerusalem every year, 2019 being the 5th event 🤓
Our team was formed out of previously random loose connections, and we were all taking a leap of faith hoping this will be a great match. Luckily, the chemistry was quick to manifest! We had a great time taking this idea from “what are we going to do” to “omg this is going to be amazing” to “ok here are the steps we should take.''
To demonstrate the VideoThat ability, we took the top 30 videos of Taylor Swift on YouTube to stand for our video data set, and as the theme song we chose “Do I Wanna Know” by Arctic Monkeys.
We each learned a lot, enjoyed our time interchanging ideas, held fruitful and insightful conversations, practiced a good work life balance during those 40 hours, and even won second place!


This is us:
Yael Daihes GitHub LinkedIn
Yaara Arkin GitHub LinkedIn
Orian Sharoni GitHub LinkedIn
Roee Shenberg GitHub LinkedIn
Dalya Gartzman GitHub LinkedIn